Generating game story with Local LLMs
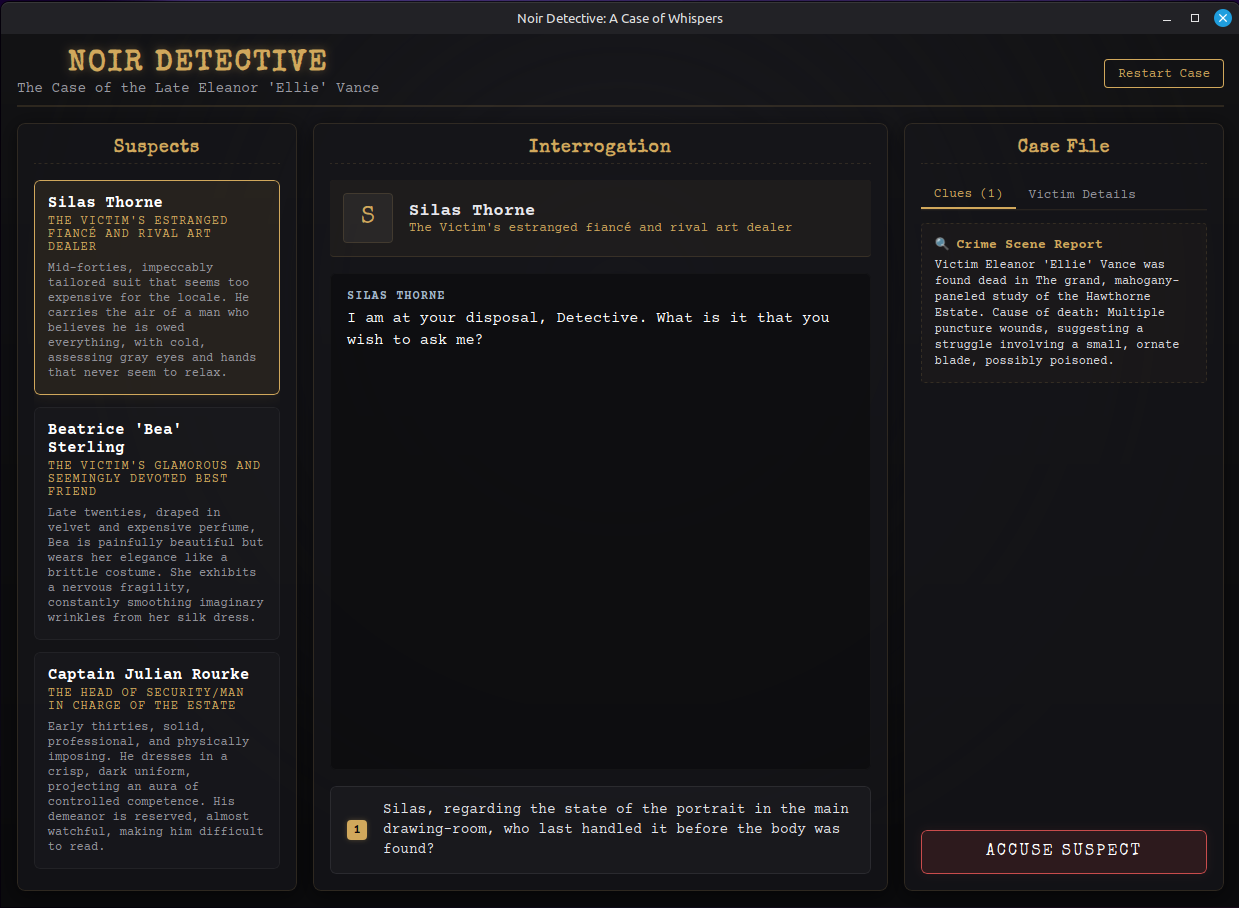
Noir Detective is a native desktop murder mystery game whose cases are entirely generated at runtime by a local LLM. The Go backend drives a three-stage prompt pipeline against Ollama, enforces strict JSON contracts, validates the resulting logic graph, and falls back gracefully when the model produces unplayable output.
This post focuses on the generation system itself: how the prompts are engineered, how outputs are sanitized and turned into usable game data, and the techniques required to make a local model produce fair, solvable murder mysteries.
The Core Problem
Large language models are excellent at atmospheric prose and character backstories. They are much worse at producing consistent, traversable logic graphs.
Early prototypes frequently produced cases where:
- The only path to the killer required a clue that was never actually revealed
- Important testimony was locked behind a prerequisite that could never be obtained
- All three suspects gave mutually exclusive but equally useless alibis
The player would reach a dead end and feel cheated. I needed a system that could both generate stories and prove they were solvable before the player ever saw them.
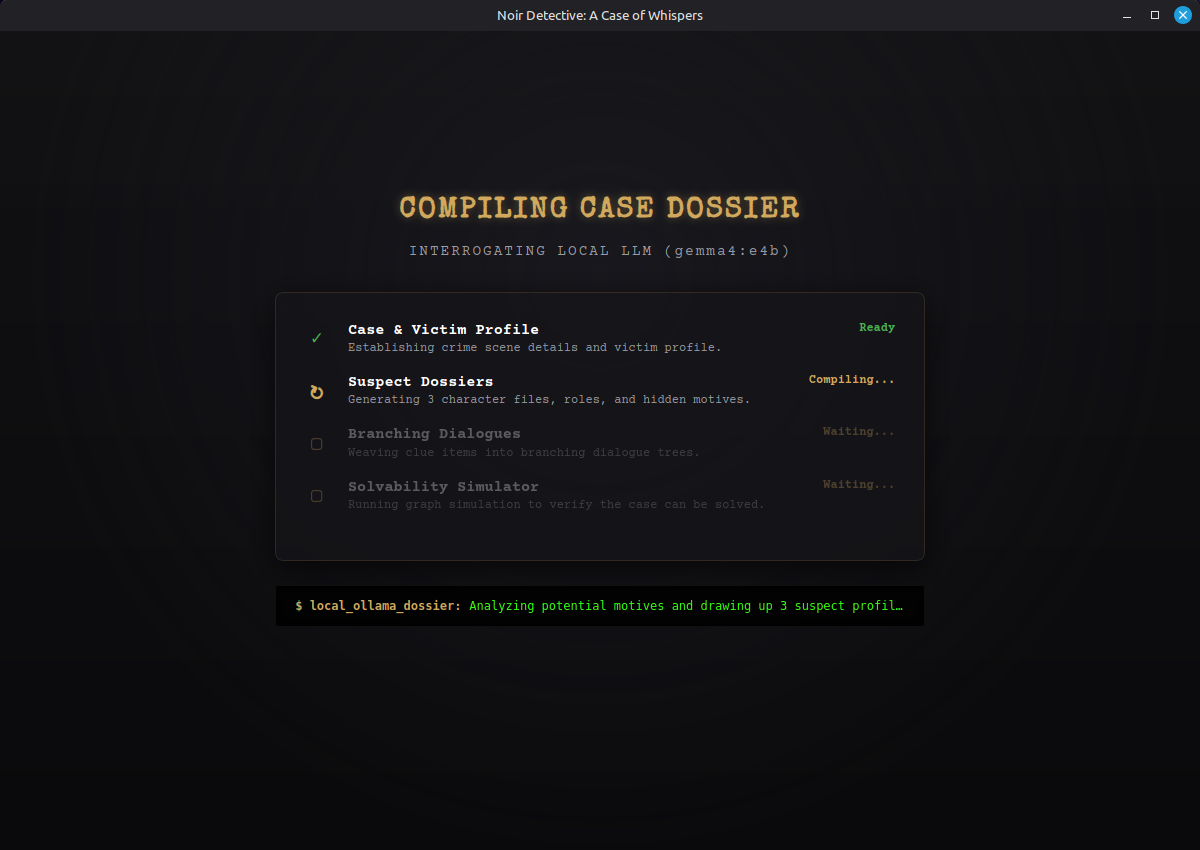
Three-Stage Generation Pipeline
Asking the model for a complete story in one shot almost always produced broken graphs. Instead, generation is split into three tightly constrained stages with strict JSON schemas.
Stage 1 establishes the foundation: a case title, a dramatic first-person detective monologue, and victim details (name, age, location, cause of death). The output is small and almost always valid.
Stage 2 creates exactly three suspects with unique IDs (suspect1–suspect3), roles, descriptions, and hidden motives, then designates one as the killer.
Stage 3 is the most important. The prompt explicitly instructs the model to build a specific clue dependency chain:
Suspect 1 must offer an initial question that reveals “clue1”. That clue must unlock a new question on Suspect 2, which reveals “clue2”, and so on until a final piece of incriminating evidence (“clue4”) proves the killer’s guilt.
This forced linear dependency gives the player a clear logical path while still allowing exploration of the other suspects.
Prompt Design and Response Processing
All interaction with the local model happens through a small queryOllama helper. It always targets gemma4:e4b, sets format: "json", disables streaming, and applies a strict 50-second timeout. Even with the format flag, the model frequently returns markdown code fences, so the response is aggressively cleaned before unmarshaling:
cleanJSON := strings.TrimSpace(ollamaResp.Response)
if strings.HasPrefix(cleanJSON, "```json") {
cleanJSON = strings.TrimPrefix(cleanJSON, "```json")
cleanJSON = strings.TrimSuffix(cleanJSON, "```")
} else if strings.HasPrefix(cleanJSON, "```") {
cleanJSON = strings.TrimPrefix(cleanJSON, "```")
cleanJSON = strings.TrimSuffix(cleanJSON, "```")
}
Stage 1 Prompt
The first prompt is intentionally narrow. It only requests a title, a noir-style detective monologue, and victim details. The JSON schema is provided verbatim in the prompt so the model knows the exact field names and nesting.
Stage 2 Prompt
Stage 2 receives the structured output of stage 1 and asks for exactly three suspects. Each suspect must have a stable ID (suspect1, suspect2, suspect3) plus a killer field indicating which one committed the murder. This stage is still relatively forgiving because no dialogue or clue logic exists yet.
Stage 3 Prompt — The Critical Contract
Stage 3 is where most of the prompt engineering effort lives. The prompt is deliberately long and prescriptive. It contains this key instruction:
You must design a solvable chain of clues linking the suspects: - Suspect 1 must have an initial question (required_clue_id: “”) that reveals “clue1”. - “clue1” must unlock a question on Suspect 2 (required_clue_id: “clue1”). - That question on Suspect 2 must reveal “clue2”. - … and so on until “clue4” provides final proof about the killer.
The model is told the exact shape of the dialogues map it must return and is forbidden from adding extra text or markdown. Every dialogue option carries required_clue_id, obtained_clue_id, clue_name, and clue_desc so the game engine can later treat the LLM output as real data.
Defensive Post-Processing
After unmarshaling, the code still applies several layers of tolerance:
- When mapping the returned dialogues back onto the three suspects, it first tries exact ID match, then falls back to fuzzy name matching (
strings.Containson both directions). - Every stage emits structured progress events so the caller can display live status even if one of the three calls is slow or flaky.
- The entire three-stage run is wrapped in a retry loop (maximum two attempts) before giving up and loading the fallback story.
These steps turn an unreliable creative model into a component that can be trusted to produce playable content most of the time.
Challenges & Lessons
JSON mode is only a hint. The model still regularly emits “json fences, so every response must be sanitized beforejson.Unmarshal`.
Stage 3 requires extreme specificity. Vague instructions such as “make the clues connect logically” produce incoherent graphs. Spelling out the exact clue flow (“clue1 from suspect1 must unlock suspect2…”) is what actually works.
Defensive mapping is mandatory. Even when the schema is shown in the prompt, the model sometimes returns dialogue keys that do not match the declared suspect IDs. A fuzzy name-based fallback saved many generations.
Two attempts is the practical limit. After the second failure the system stops and loads the fallback. Longer retries hurt the experience more than a hand-written case does.
The most valuable prompt technique was turning the desired game mechanic (a solvable clue chain) into an explicit structural requirement inside the prompt itself rather than hoping the model would discover the right shape.
Summary
| Component | Technology |
|---|---|
| LLM Runtime | Ollama (gemma4:e4b) |
| Generation Strategy | Three-stage prompt chaining |
| Structured Output | JSON mode + aggressive fence stripping |
| Reliability Layer | Schema validation + two-attempt retry |
| Fallback Strategy | High-quality hand-authored case |
The generation system shows that local LLMs can produce usable narrative content for games, but only when the prompts are treated as executable specifications and every model response is processed through multiple layers of defensive sanitization and validation.
Thanks

If you’re interested in following future experiments with local models for structured narrative generation, or have questions about the prompt chaining approach, feel free to reach out on X: @imdonix.